故障服务定位算法综述
因为在部署,扩展以及自动化等方面的优势,基于服务的架构或者微服务架构被越来越多的系统采用。
这样的系统会包含几十到上百个服务(包括微服务,下同),每个服务可能部署在若干台宿主机上。
为了保障系统的稳定运行,运维人员往往会在每个系统上收集多种指标(例如,系统成功率,响应时间等),并且利用这些指标进行异常检测。
尽管如此,当此类系统发生故障时,定位故障仍然是很困难的。
因为在此类系统中,一个用户请求需要众多服务通过互相调用的方式共同实现。
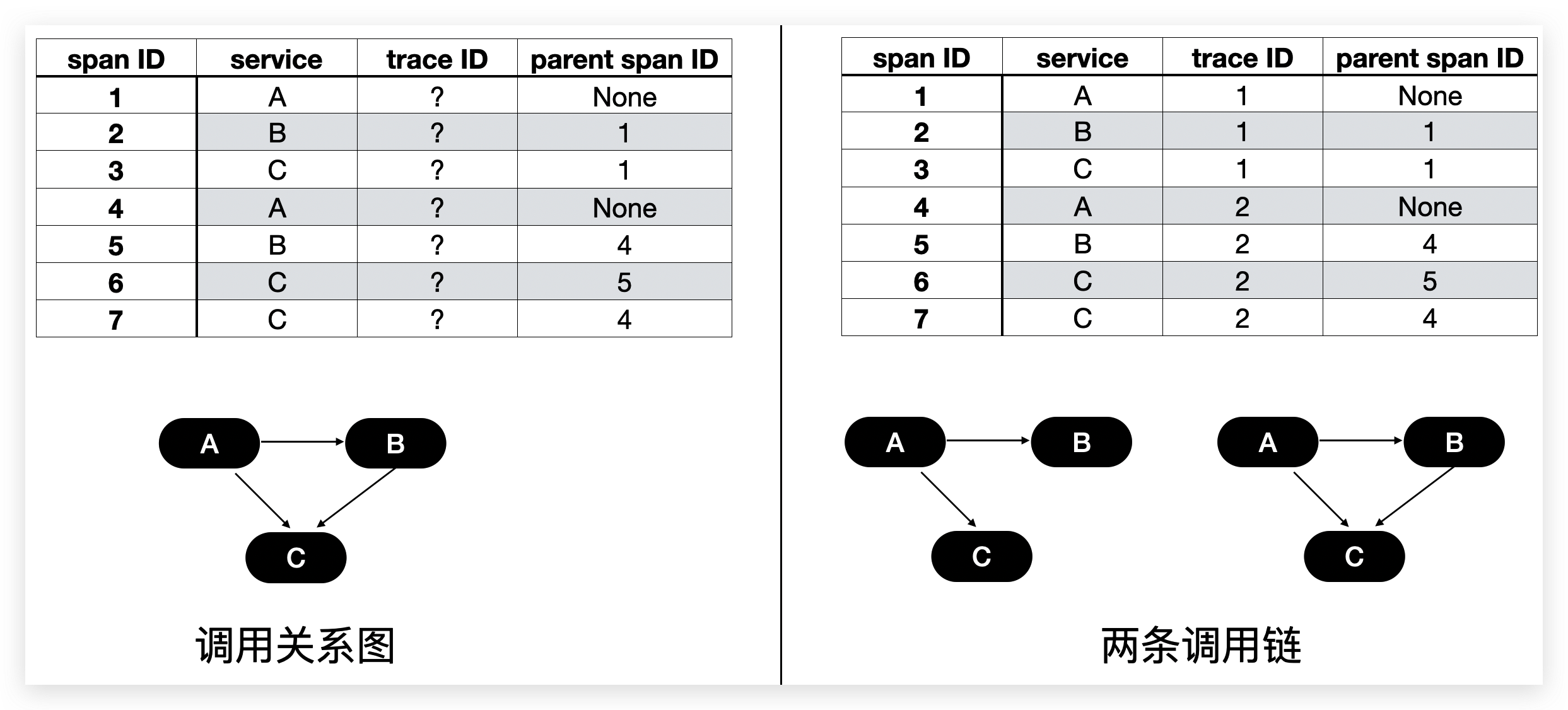
这些实现同一个用户请求的调用被称为一个调用链。
一般的实现是通过对每个调用标注全局调用链ID来标识每个调用属于的调用链,但是在很多系统的视线中,并没有全局调用链ID,也就没有办法知道哪些调用属于一条调用链。
当故障发生时,真正有故障的服务和与它相关的服务,都会出现指标异常以及发出告警。
大量的告警让运维人员无法确定哪个服务才是故障根因,只能逐个服务去检查,排除掉那些本身并没有异常的服务。
对于某些大型系统,不同的服务是由不用的运维人员甚至不同的部门管理的,因此故障定位涉及到不同人员甚至不同部门的合作,故障定位成本非常高。
因此,自动化的故障根因服务定位算法对于快速处理基于服务的系统的故障是很重要的。
实现这种算法的主要挑战有三点。
首先,服务之间复杂的依赖关系非常复杂,难以分析故障在服务之间的传递。
其次,基于服务的系统往往更新迭代频率较高。
最后,系统中会存在大量的指标,系统中存在大量的服务,每个服务有很多指标,每个服务部署在多台宿主机上,每台宿主机上也会有很多指标。因此和故障相关的指标会淹没在海量的指标中。
最近这些年来,出现了许多聚焦于自动化的故障根因服务定位的方法:RCSF1,CloudRanger2, MS-Rank3, Monitor-Rank4, TPDS175, TON186, MicroScope7, MEPFL8, AutoMAP9, JSS211, RCA12,RCA-KDD13, CRD14等等。
有些方法是基于调用的,这些方法的基本思想是利用调用信息推断故障的传播。
如果有调用链信息,那么可以基于调用链进行定位。
从方法的角度讲,这些方法可以整理为这样的一个表格:
| 基本方法 | 随机游走 | 因果分析 | 相关关系消失 | 基于历史故障 | 关联规则挖掘 | Others |
|---|---|---|---|---|---|---|
| 工作 | [2,3,4,6,9] | [2,3,7,9] | [14,15] | [5,8,11,2,9] | [1] | [12] |
此外,从使用的数据的角度,以上的方法,根据利用的信息从少到多可以分为两个层次:
- 只有每个节点的指标信息,或者节点之间的调用信息。[1, 2, 3, 4, 5, 6, 9, 11, 14, 15]
- 有全局调用链ID可以串起来不同的单次调用。 [7, 8, 12]
我们将分类介绍这些调用链根因定位算法。在这里,我们没有去研究那些主要聚焦于调用链采集、调用链可视化系统等相关的工作,而是聚焦在根因定位算法方面。
基于随机游走的方法¶
MonitorRank¶
背景¶
MonitorRank4是最早使用随机游走的策略定位故障根因服务的方法,是来自LinkedIn的工作,发表于SIGMETRICS’13。
MonitoRank把系统的服务分成三类:
- 前端服务,负责接收用户的请求以及进一步调用下游请求以完成用户的请求。
- 应用服务,负责真正处理用户请求的逻辑
- 数据服务,负责提供经过包装的数据
应用服务和数据服务又统称为后端服务
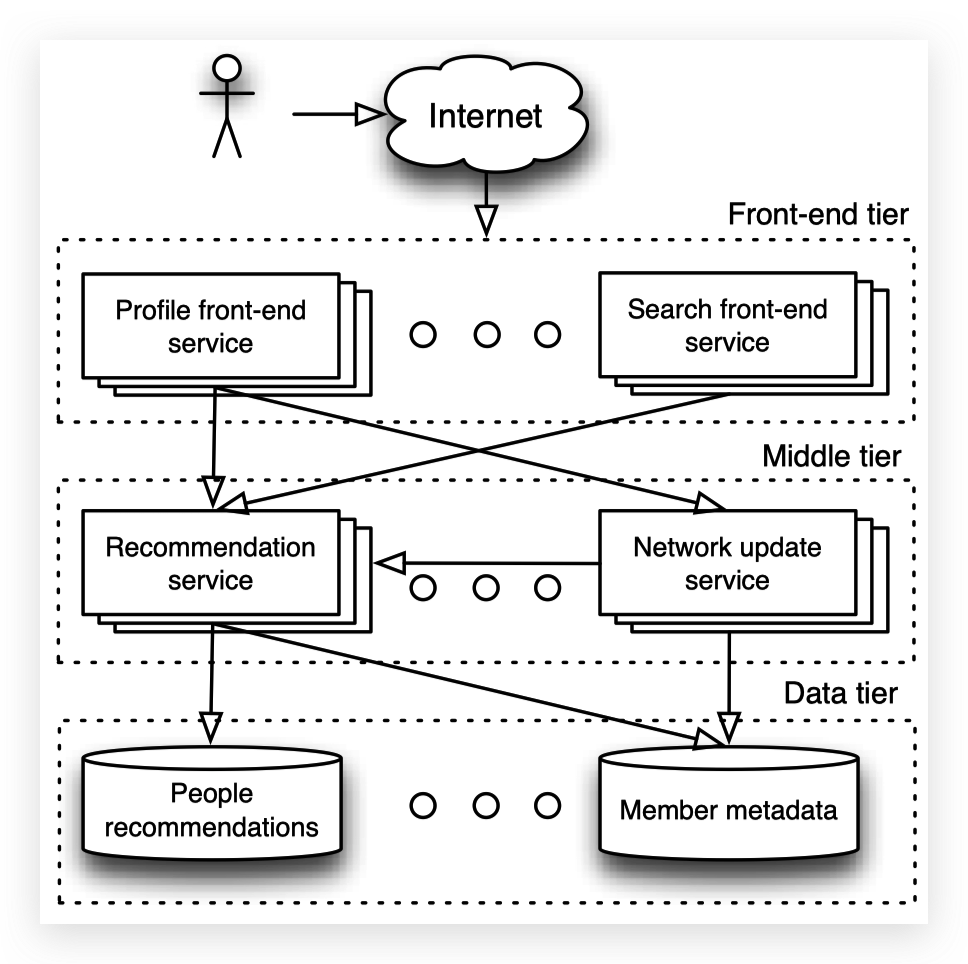
在每个服务上,配置有传感器,会定时给出指标数据。通过服务之间的调用关系,可以形成一个调用拓扑图。
图上的节点就是服务,边就是节点之间的调用关系。
基于这样的数据,MonitorRank把根因服务定位问题定义为,给定告警指标\(m\),告警前端节点\(v_{fe}\)和时间\(t\),根据剩下其他节点的指标\(m\)的值,对所有节点进行排序。
MonitorRank和我们研究的其他很多文献一样,只聚焦在异常发生之后的故障定位,和大量的异常检测的相关工作区分开来了。
故障定位¶
现在假设我们有了服务之间的调用图(稍后再来看MonitorRank是如何获取调用图的),MonitorRank是如何定位根因(即排序所有节点)的呢?
MonitorRank基本思想是,一个节点的指标\(m\)和异常前端节点\(v_{fe}\)的指标\(m\)的相关性表示了该节点是根因的可能性。
由于非根因节点也可能有很高的相关性,所以相关性高只是一个必要条件,相关性高的节点作为候选,后续再进行进一步的分析。
我们如果从任何一个怀疑的节点开始入手,根据调用关系图,我们查看它是不是依赖其他高相关性的节点,如果是,那么我们的怀疑就转移到它的邻居去,以此类推。
即,依次选择一系列节点,每次都根据转移概率(目标节点和异常的相关性)从上一个节点的邻居中选择下一个节点。
MonitorRank假设在许多次随机游走过程中,被访问越多的节点越可能是根因,即被访问的概率就是根因排序依据的分数。
这样的随机游走过程其实就是Weighted PageRank的过程,鉴于我们完全不怀疑相关性低的节点,MonitorRank采用了Personalized PageRank10,对每个节点的偏好程度(personalization)就是它的相关性。
我们形式化地描述MonitorRank的具体算法,给定图\(G=<V, E>\)。\(V\)是服务的集合,如果服务\(v_i\)调用了\(v_j\),那么\(e_{ij}\in E\),否则\(e_{ij}\notin E\)。\(\mathbf{A}\)是\(G\)的邻接矩阵。
向量\(\mathbf{S}\)定义了每个节点和异常前端节点指标\(m\)的相关性,即\(S_i=\text{similarity}_{m}(v_i, v_{fe})\)。
那么转移概率矩阵可以定义为\(Q_{ij}=\frac{A_{ij}S_j}{\sum_{k}A_{ik}S_k}\),即节点\(v_i\)转移到节点\(v_j\)的概率和\(S_j\)成正比,且仅当\(v_i\)调用了\(v_j\)时才转移。
根据以上定义,每个节点都必须转移到它的一个邻居(因为\(A_{ii}=0\)),但是实际上可能一个节点本身就是根因,不需要转移到其他邻居节点去了。
这会导致随机游走不得不游走到相关性很低的节点上。
因此MonitorRank在\(Q\)的基础上额外定义了自环,自环的概率代表的就是一个节点本身就是根因的概率。
所以如果一个节点所有依赖的节点相关性都不高(比自己还低就是不高),那么这个节点的自环概率就应该相应更高。
所以自环的转移概率(未归一化)定义为:\(S_i-\max_{j:e_{ij}\in E}S_j\)
因为相关关系并不代表真正的因果关系,所以以上定义的转移概率可能是有错误的,然而,一旦随机游走时因为错误的概率定义游走到了错误的分支上,就再也没有机会纠正了。
因此MonitorRank给每一条边都引入了反向边,反向边的权重就代表了转移概率错误的概率:\(\rho S_i\)(未归一化),其中\(\rho\)是一个超参数。
因此,完整的转移概率矩阵\(P\)定义为
Personalized PageRank Vector \(\pi_{PPV}\)就是每个节点是故障根因的概率,可以通过解如下方程得到
其中\(\alpha\)是Personalized PageRank Vector算法的参数。
故障图提取和外部因素¶
上述的故障定位流程是在异常发生后触发的。
而MonitorRank方法还会周期性地运行对所有指标数据调用关系的分析,得到调用图。
当触发故障定位时,直接使用最新的调用关系图。
另外,服务之间的依赖关系并不只有调用关系,比如两个服务竞争同一个外部资源。
在外部因素的具体化中, 我们会介绍其他一些工作是如何考虑更具体的外部因素的影响的。这种情况下,即使两个节点之间没有调用关系,它们之间的转移概率也应该更大。
MonitorRank周期性地基于每一个前端节点对剩下的所有节点进行条件聚类。
当触发故障定位之后,MonitorRank首先选择一个最合适的类,然后把类中每一个节点的相似度\(S_i\)都再额外加上此类的平均相似度,以此表达类内的所有节点都和异常前端节点受同一个外部因素的影响。
外部因素的具体化¶
TON186将MonitorRank中考虑的外部因素具体化为虚拟机之间部署在同一台宿主机的关系。也就是说,TON18使用的故障传播图包含了调用关系和竞争同一台宿主机的资源的关系。
在MicroScope7中,类似的共享资源的依赖关系也被考虑了,文中称之为 non-communicating serviced denpendency.
这些更具体化的外部因素,是通过准确的虚拟机部署位置等信息得到的。相比MonitorRank使用的聚类方法,优点是这种依赖关系是准确的、可解释的,缺点是可能漏掉更多的其他的外部因素。
基于因果分析进行随机游走¶
MonitorRank4和TON186使用的方法,都是使用调用关系导致的依赖关系作为基础,加上共享资源等外部因素导致的依赖关系,建立了故障传播图,并基于此进行随机游走。但是节点之间可能还是存在未定义的依赖关系的类型。既然如此,直接从数据中挖掘节点之间的依赖关系可能会更加通用。
CloudRanger,MS-Rank和AutoMap等都是基于PC算法,构建出节点之间的依赖关系图谱(被称为impact graph或者anomaly behavior graph)。该依赖关系图是一个有边权重的有向无环图,之后的随机游走是基于图谱上的边权重计算转移概率。这几个方法使用的依赖图基本相同,大致的步骤如下:
-
初始化一个无向的完全图,边的权重都是1。
-
检查所有的边两端节点的条件独立性,如果给定任一节点集\(\mathbf{v}\)的情况下\(v_i, v_j\)的指标是条件独立的,那么就设置\(w_{ij}=0\),并且将\(\mathbf{v}\)加入\(Con_{ij}\)和\(Con_{ji}\)
- 去掉权重为0的所有边
- 基于v-structure给每一条边指定方向,具体方法为:
- 搜索图上所有三元组\((v_i, v_j, v_k)\),使得\(e_{ij}\in E, e_{jk}\in E, e_{ik}\notin E\),并且\(v_j\notin Con_{il}, v_j\notin Con_{li}\),则将边的方向指定为\(v_i \rightarrow v_j \leftarrow v_k \(。因为\)v_i, v_j\)和\(v_j, v_k\)都相关,那么它们就受同一个节点影响;又因为\(v_i, v_k\)条件独立,所以不会是\(v_i\)或者\(v_k\)。
- 对于任何不能通过v-structure指定方向的边,通过不断使用以下三个规则确定方向。基本思想是检查每条边的两个可能的方向是否会引入新的v-structure或者导致环。
- 如果存在\(v_i\)使得\((v_i, v_j) \in E\)且\(e_{ik}\notin E\),则将\(e_{ij}\)方向指定为\(v_j\to v_k\)。否则\((v_i, v_j, v_k)\)就是一个新的v-structure。
- 如果存在\(v_i\to v_k \to v_j\),则将\(e_{ij}\)方向指定为\(v_i \to v_j\)
- 如果存在\(v_i - v_k \to v_j\)和\(v_i - v_l \to v_j\),并且\(v_k\)和\(v_l\)条件独立,则将\(e_{ij}\)方向指定为\(v_i \to v_j\)。否则要么会引入环,要么\(v_k, v_i, v_l\)会形成新的v-structure

这种方法一个显而易见的问题是:系统中的节点可能存在循环依赖关系,但是这个依赖关系挖掘的算法忽略了这种情况。
这里得到的依赖关系图表达了每两个节点的因果关系,所以在这里随机游走的转移概率定义中,\(P_{ij}\propto w_{ij}\cdot S_j\),其中\(w_ij\)是边\(v_i\to v_j\)的权重。
随机游走方法的改进:二阶游走¶
CloudRanger2对MonitorRank中采用的Personalized Page Rank提出了一种改进。
MonitorRank中使用的PPR,每一步的转移概率只和当前所在的节点有关:\(P_{i,j}=P[X_{t+1}=v_j|X_t=v_i]\)。
CloudRanger则采用了二阶游走,认为转移概率和上一步转移的来源也有关:\(P_{i,j,k}=P[X_{t+1}=k|X_t=j, X_{t-1}=i]\)。
从另一个角度理解,二阶游走实际上是边到边的随意游走。
和MonitorRank一样,在CloudRanger中,随机游走的概率仍然取决于目标节点和异常前端节点的相似度。记\(v_i\to v_j\)和\(v_j\to v_k\)的一阶转移概率为\(p_{ij}\)和\(p_{jk}\),则\(p_{i,j,k}\propto (1-\beta)p_{ij}+\beta p_{jk} \(,其中\)\beta\)是给定的超参数。当\(\beta\)等于\(1\)的时候,即等价于一阶的随意游走。
二阶游走的动机是有趣的,但是具体在什么样的情况下会有用,CloudRanger2中并没有给出具体例子,也没有量化评测对比和一阶随机游走的差别。尽管二阶游走是兼容一阶随机游走的,但是在带来的好处不明确的情况下引入更多的参数并不是好主意。
基于多指标的随机游走¶
上面提到的MonitorRank和CloudRanger都是基于异常前端节点的异常指标和每个节点的对应指标的相似度来计算的。但是在实际场景中,异常前端节点可能并不只一个指标异常,而且前端节点和根因节点的异常指标可能不同。例如,根因系统因为硬件故障导致无响应,导致上游调用响应时间增加。因此此时只用单个指标就难以准确定位到真正的根因节点。
MS-Rank3和AutoMAP9使用了多个指标进行随机游走,具体的方法把多指标得到的转移概率进行加权平均:\(P_{ij}\propto \sum_{m}W_{m, i, j}S_{m, j}\),其中\(S_{m,j}\)是节点\(v_j\)和异常前端节点\(v_{fe}\)的指标\(m\)的相似度,\(W_{m,i,j}\)是节点\(v_i, v_j\)之间指标\(m\)的权重。
MS-Rank和AutoMAP使用了不同的思路去计算权重\(W_{m,i,j}\),但是共同点是需要引入历史故障的定位结果。MS-Rank维护一个最佳的权重,AutoMAP会为每次定位计算一个最佳的权重。
MS-Rank计算了在历史数据中,基于每个单独的指标\(m\)定位的结果的精确率(top-k precision) \(P(m)\)。对于每个节点\(v_i\),\(W_{m,i,j}=W_{m, i}\propto P(m)\),其中只计算\(v_i\)为根因的历史故障。这样的方法基本思想是,如果过去只通过指标\(m\)定位到\(v_i\)为根因的次数越多,那么就越依赖指标\(m\)。但是首先,这里\(W_{m,i}\)是计算从\(v_i\)向外转移时的指标权重,但是利用的却是\(v_i\)作为根因时的历史数据。其次,可能有的节点\(v_i\)从来都没有成为过根因,尤其是考虑到有准确根因记录的事件数量并不会很大。
AuotMAP中,\(W_{m,i,j}=W_{m}\),即指标的权重和节点无关,每个指标全图只有一个权重\(W_m\)。\(W_m\)通过历史故障数据中,和当前的依赖关系图(anomaly behavior graph)最相似的k个故障数据中的,根因节点和异常前端节点的指标\(m\)的相似度的加权平均得到,权重是每个故障的定位精确率。即\(W_m=\sum_{j=1}^{k}P(G_j)S_{m, rc_j}\),其中\(G_j\)是每个故障的依赖关系图,\(P(G)\)表示使用\(G\)作为依赖关系图时的精确率。
不同方法的对比和总结¶
所有这些基于随机游走的方法都基于一个假设:根因微服务的某个指标和异常前端节点相似。这里可能存在的问题包括:
- 当故障发生时我们对于每一个异常前端都需要进行一次定位,并不是所有系统都有一个唯一的入口服务。
- 如果当系统中同时出现两个故障时,每个后台服务可能会受到叠加的影响
- 故障节点和异常前端节点之间经过的其他服务较多的时候,异常前端节点的指标中受故障节点的影响的比例可能会很小,导致它们的指标可能并不特别相似。这和具体的相似性计算方法也很有关系,上述方法应用的都是某种形式的perason correlation。
- 指标相似和根因可能没有必然关系。例如这是我们在实际生产系统中遇到过的一种情况:调用关系为\(A->B->C\),其中调用\(A\to B\)和\(B\to C\)的响应时间都大大增加了,B和C响应时间都和A的响应时间是相似的。但是根因系统是\(B\)而不是随机游走的重点\(C\),因为大部分的请求只到\(B\)就结束了,并没有进一步调用\(C\)。
另一个重要的问题是基于调用关系图还是通过PC算法得到的相关关系图进行随机游走,这两个表达的依赖关系是有重叠的,但是都没有能完全覆盖所有的依赖关系。
在AutoMAP9中,作者对比了MonitorRank,CloudRanger,MS-Rank和AutoMAP。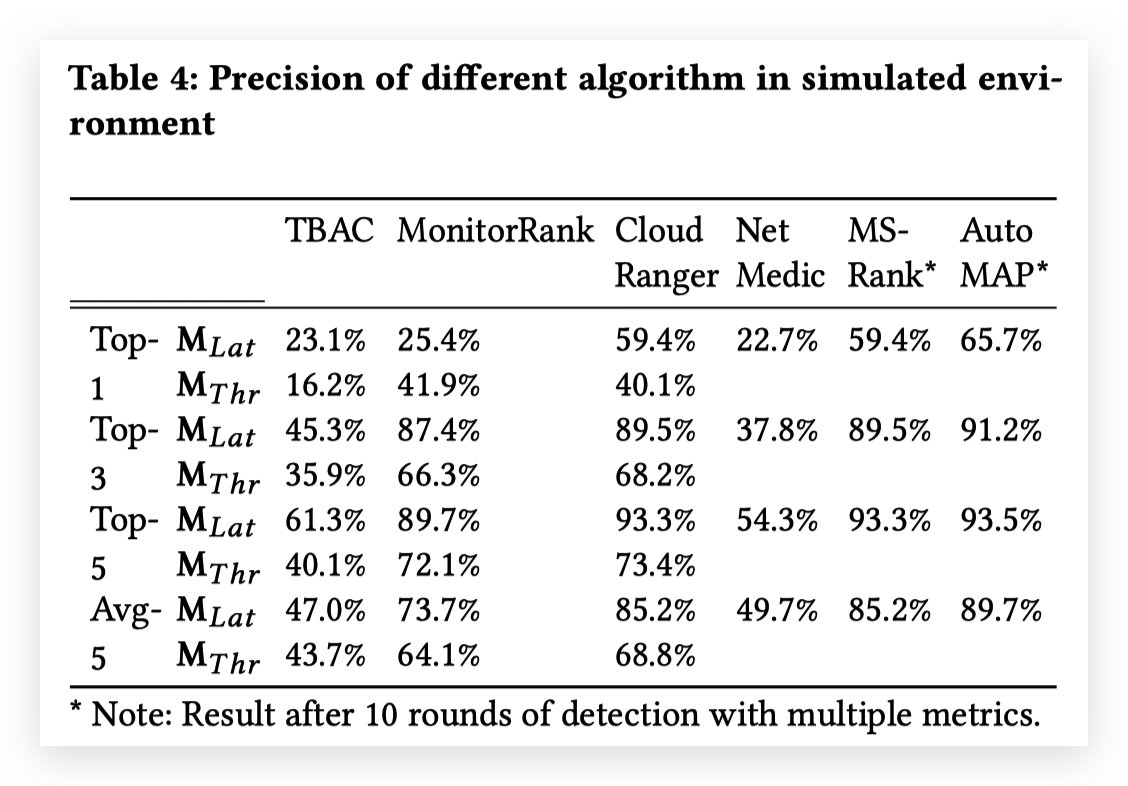
CloudRanger(使用延迟latency作为指标)和MS-Rank的结果完全相同。考虑两个方法十分相似,不同点只在于CloudRanger使用的是二阶游走,MS-rank使用了多指标综合,这两个方法使用的改进效果应该都比较有限。AutoMAP的结果比两者有少量提升,说明AutoMAP的多指标结合的方法更加有效。CloudRanger和MonitorRank的效果对比的话,只是略有提升,说明使用依赖关系图和调用关系图造成的影响也有限。
但是这个对比是基于一个很小的benchmark系统,Pymicro的;而且故障的数量和种类都比较有限,所以对比结果并不一定说明普遍情况下的优劣。
基于因果分析的方法¶
因果分析(causality analysis)在很多方法中被用来推断节点之间的依赖关系,基于这个依赖关系再进行进一步的分析。
基于因果图进行随机游走¶
在之前的章节中,我们已经介绍过,CloudRanger基于因果分析得到节点之间的依赖关系,然后再基于这个依赖关系图进行随机游走得到根因。
基于因果图和调用链追溯根因¶
如果有了全局调用链ID信息,能够知道那些请求是属于同一个调用链的,那么依赖图可以更直接被使用。
简单来说,如果一个节点是异常的,并且它所依赖的节点都是正常的,那么它的异常应当是由自己导致的,自己就是故障的根因;否则,应该递归地去分析它所依赖的异常节点。
MicroScope7就采用了这样的方法,它利用PC算法(参见 基于因果分析进行随机游走)分析得到节点之间的依赖关系。当故障发生时,MicroScope从每条异常调用链的终端节点触发,利用上述原则,通过深度优先遍历(DFS)得到这一条调用链的根因节点。为什么不直接基于调用关系做这件事?因为调用关系和依赖关系有相交但是并不相等。共同依赖外部资源就是调用关系之外的依赖关系。
虽然MicroScope只针对单条调用链定位其根因,但是我们可以(也应当)把故障时间段内大部分异常调用链的根因当作整个系统的故障的根因。
MicroScope采用的DFS的方法使得其只能分析无环的依赖关系调用链,但是节点之前完全可以有互相依赖的情况。
MicroScope的核心思想是分析出(在正常时刻)节点之间的依赖关系,然后只要一个节点的依赖有异常,那么就会认为它的异常是由依赖的节点导致的。
基于消失的相关关系的方法¶
这一类方法1314只知道每个节点的指标信息,连节点之间可能的调用关系也不清楚。基于AutoRegressive eXogenous(ARX)模型,我们可以得到每两个指标(节点)之间的相关性。基于此可以得到一个无向图(invariant network, IN),图上的边代表两个节点的指标有相关关系,被称为invariant link。当故障发生的时候,由于节点运行状态的变化,相关关系会消失,这样的边被称为broken link。

所以可以把根因定位问题这样看待:当故障发生的时候,我们得到了一个带broken link的IN,我们需要定位最可能导致这些broken link的节点。RCA-KDD13对这个问题建模进行了完整的描述并提出了一个理论基础坚实的解决方案,是KDD 2016的最佳论文候选。
所以首先我们需要对故障传播关系进行建模。每个节点的直观观测到的异常程度和潜在的根因程度分别用向量\(\mathbf{r}\)和\(\mathbf{e}\)表示。RCA-KDD做了两个假设,1) 同一个节点的\(e\)和\(r\)应当尽量接近;2)相关性越强的节点的\(r\)应该越接近。因此可以得到一下的故障传播问题,其中\(\mathbf{A}\)是IN的邻接矩阵,\(\mathbf{D}\)是的度数矩阵。
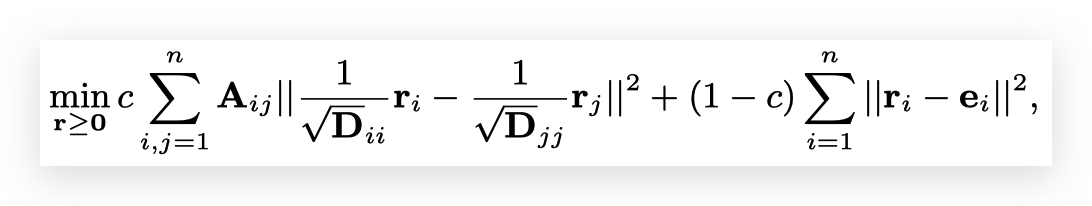
上述问题有解析解:
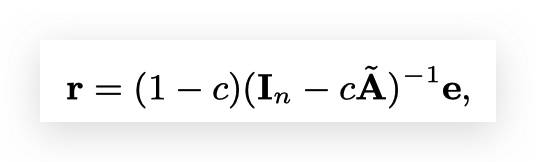
当得到故障传播的结果(\(\mathbf{r}\))之后,可以得到对broken IN的估计。如果两个节点本来是有相关关系的,但是两个节点的\(r\)都很大,那么他它们之间的边就越可能是broken link。因此只需要优化\(\mathbf{e}\),最小化重构出来的broken IN和实际的IN的差别即可。向量\(\mathbf{e}\)就是每个节点的根因分数。
RCA-KDD提出了一个保证收敛性的迭代算法解上述优化问题,并且在一个实际数据集上验证了性能。
CRD是对RCA-KDD的改进,主要的改进点是考虑节点会分成不同的组,故障会倾向于在组内传播。
RCA-KDD和CRD基于两个假设,提出了解决invariant network的有理论基础的有效方法。除了这两个假设在实际中的有效性之外,利用它们解决根因定位还有一个鸿沟,就是invariant network和实际的依赖关系并不相同。至少实际的依赖关系应该并不会是无向图(或者说是权重相同的双向的有向图)。
基于已知故障数据的有监督方法¶
利用历史数据优化参数¶
第一节介绍了基于随机游走的方法,其中CloudRanger和AutoMAP需要利用已知的故障数据优化综合多指标相关的参数,因此他们也被列入此类。
如果有了足够的已知故障数据,是不是可以设计出对领域知识依赖更少的方法?
匹配相似故障¶
如果假设同一个故障总会导致相同的故障表现,我们就可以基于历史上发生的故障的异常表现和定位到的根因,推断当前的故障的根因。
这两个工作511 记录异常的特征,和人工定位的结果,建立一个历史故障的数据库,当新的故障发生的时候,就基于当前的异常特征,寻找历史上出现过的最相似的故障的定位结果,推荐给运维人员。
机器学习¶
故障根因和异常表现之前可能存在一些内在的逻辑,然而直接匹配历史上相似的异常并不能学习到这种内在逻辑,只能处理已经出现并定位过的故障。
MEPFL8把单条调用链的根因节点定位问题看作多分类问题(每个类别就是根因是某一个节点),使用端到端的有监督机器学习模型(随机森林,神经网络)解决这个问题。MEPFL的重点并不是机器学习,因此它只是简单地调用脸scikit-learning里面的KNN,RF和MLP这些包去做机器学习。MEPFL利用领域知识,将一个调用链编码为以下这些特征:
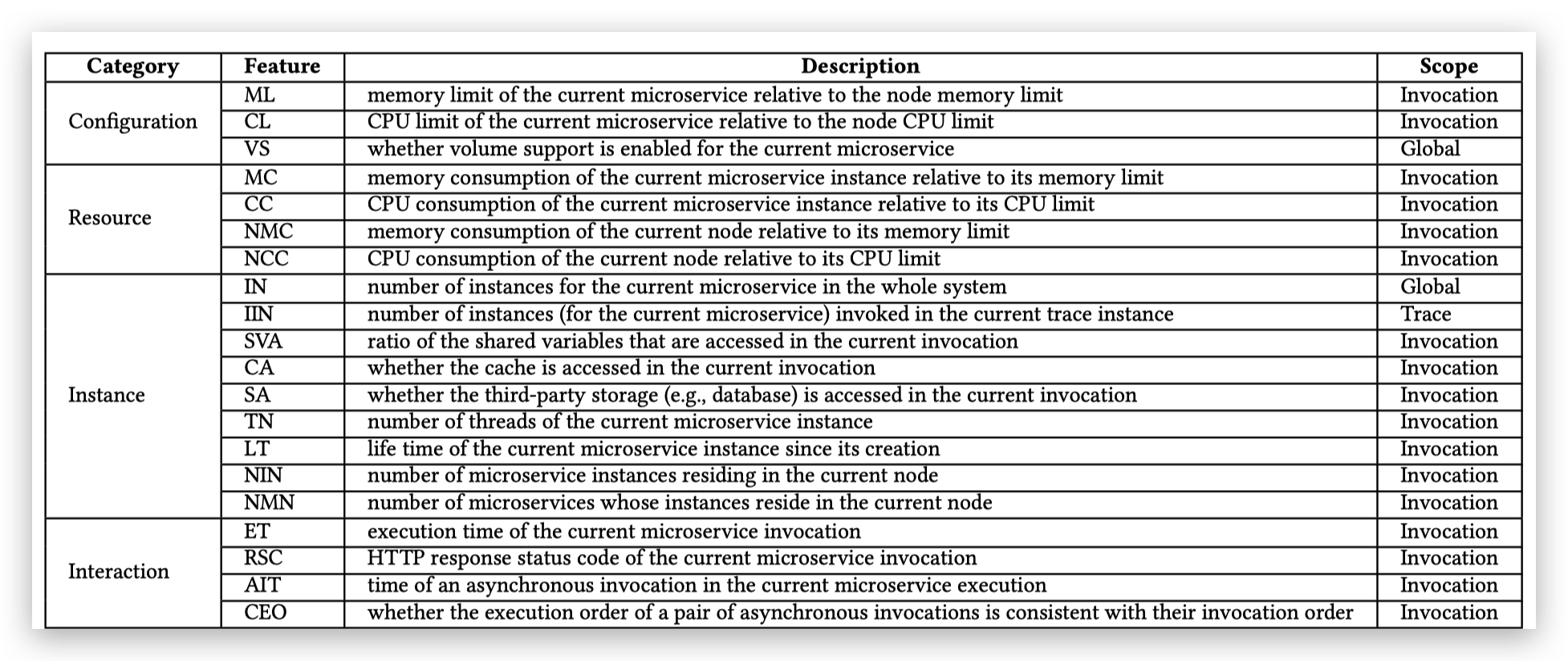
MEPFL用的方法能取得非常好的效果。另外,从下图可以看出,MEPFL确实可以成功定位没有见过的异常调用链类型(一种特定故障注入在一个特定的微服务上是一种类型)。和MicroScope一样,MEPFL只处理单条调用链并不是实质性的问题。
有监督方法的问题¶
这一类方法单纯比较定位的准确性是最强的,但是非常依赖足够的有标注数据。“足够”指的不是数据的量足够,而是指收集到的故障数据要覆盖尽量多的故障类型。
在实际的生产系统中积累有根因节点标注的故障数据必然是相当缓慢的,所以上述方法中会通过人为注入故障并收集对应的数据,得到更多的有标注的数据。但是在实际的生产系统中,注入数据就要求我们需要维护一套和生产系统规模相近的系统,并在上面注入足够大的流量,这样做的开销非常大。另一方面,需要有注入足够多类型的故障,有监督方法,包括MEPFL,对于完全陌生的故障是无能为力的。
尽管在MEPFL中,作者证明可以在训练集覆盖的故障调用链类型只有10%的情况下取得过得去的性能,但是实际上,这里不同类型的故障类型只有三类(一方面原因是MEPFL只考虑软件本身实现和配置的故障),故障调用链类型是考虑了注入在不同的节点上。但是,实际中的故障类型不胜枚举,如果是完全没有见过的故障类型,有监督方法能不能只用这么少数的故障类型训练得到的模型去定位新的故障类型的根因,就是一个问题了。
解决这一问题以下的策略可能是有帮助的:
- 半监督学习。通过引入部分领域知识,减少对标注数据的依赖。用了标注数据可以提升效果,没有的话效果也还过得去。AutoMAP这样的方法就有这种效果。
- 迁移学习。在一个完全受控制的测试系统上注入足够多类型故障,用这些数据训练模型。然后将其迁移到实际的生产系统上做检测。或者可以利用生产环境上少量的标注数据对模型进行微调以进一步提升效果。
基于关联规则挖掘的方法¶
RCSF1认为通过挖掘调用链路图上异常最集中的部分可以找到根因。
具体来说,首先我们通过调用数据得到节点之间的调用关系图。如下图,我们得到节点之间的调用关系。
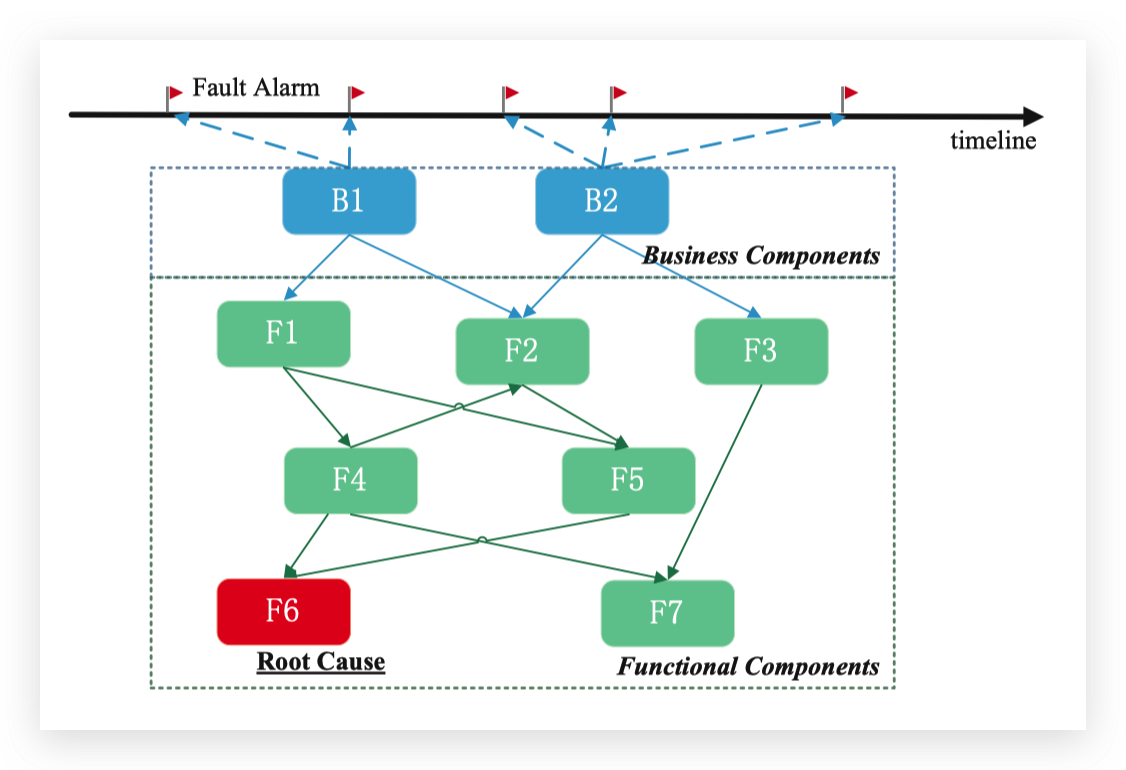
然后当告警发生时(例如上图中B1触发告警),对所有节点进行异常检测,得到异常的节点。根因节点至少需要是异常的。例如在上图中,检测出F2和F6都是异常的。
之后生成所有从异常节点到根因节点的路径,在上图中有:\(F6\to F4\to F1\to B1\), \(F6\to F5\to F1\to B1\), \(F6\to F5\to F2\to B1\), \(F2\to B1\), \(F2\to F4 \to F1 \to B1\), \(F6\to F5\to F2 \to F4 \to F1 \to B1\).
最后从上面生成的序列中挖掘频繁子序列,这就是最后的根因。RCSF中采用的是基于SPAM算法,不过这里具体采用的算法只是影响挖掘频繁子序列的效率了。
RCSF的出发点很合理,但是RCSF生成的路径只是基于调用关系图的纸面路径而已,和实际的调用链路没有关系。
其他方法¶
RCA12中,将每一个节点的响应时间\(t_1, t_2, ..., t_n\)和调用链的总响应时间\(T\)建模为\(T=t_1+t_2+...+t_n\)。RCA将这个视为一个线性回归模型,通过LMG算法将线性回归的\(R^2\)分解到每一个节点的响应时间\(t_i\)上,即得到每一个节点的响应时间的变化对总响应时间的变化的贡献。RCA将其命名为相对重要性(relative importance)。
RCA通过每个节点的相对重要性对所有的节点排序,越重要的就越可能是根因。
结论¶
以上方法并没有最优的一个,而是在各自有不同的适用范围。
当有足够的历史故障数据,并且有调用链ID的时候,MEPFL用的有监督机器学习方法可以取得所有方法里最佳的性能。
如果没有历史故障数据,但是有调用链ID,类似MicroScope这种基于调用链进行定位比基于整个系统的调用图定位会更加精准。
如果没有调用链ID,但是有足够的历史故障数据,匹配历史相似故障是可行的方案,或者可以利用历史故障数据优化随机游走等无监督方法的性能。
如果没有调用链ID,也没有足够的历史故障数据,主要的方法就是随机游走,这些方法之间的不同主要是如何确定节点之间的依赖关系以及如何确定转移概率。但是大的方向总是分析异常节点和它的直接邻居之间的关系。
参考文献¶
-
K. Wang et al., “A methodology for root-cause analysis in component based systems,” in 2015 IEEE 23rd International Symposium on Quality of Service (IWQoS), Jun. 2015, pp. 243–248, doi: 10.1109/IWQoS.2015.7404741. ↩↩
-
P. Wang et al., “CloudRanger: Root Cause Identification for Cloud Native Systems,” in 2018 18th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), May 2018, pp. 492–502, doi: 10.1109/CCGRID.2018.00076. ↩↩↩
-
M. Ma, W. Lin, D. Pan, and P. Wang, “MS-Rank: Multi-Metric and Self-Adaptive Root Cause Diagnosis for Microservice Applications,” in 2019 IEEE International Conference on Web Services (ICWS), Jul. 2019, pp. 60–67, doi: 10.1109/ICWS.2019.00022. ↩↩
-
KimMyunghwan, SumbalyRoshan, and ShahSam, “Root cause detection in a service-oriented architecture,” ACM SIGMETRICS Performance Evaluation Review, Jun. 2013, doi: 10.1145/2494232.2465753. ↩↩↩
-
C. Pham et al., “Failure Diagnosis for Distributed Systems Using Targeted Fault Injection,” IEEE TRANSACTIONS ON PARALLEL AND DISTRIBUTED SYSTEMS, vol. 28, no. 2, p. 14, 2017. ↩↩
-
J. Weng, J. H. Wang, J. Yang, and Y. Yang, “Root Cause Analysis of Anomalies of Multitier Services in Public Clouds,” IEEE/ACM Transactions on Networking, vol. 26, no. 4, pp. 1646–1659, Aug. 2018, doi: 10.1109/TNET.2018.2843805. ↩↩↩
-
J. Lin, P. Chen, and Z. Zheng, “Microscope: Pinpoint Performance Issues with Causal Graphs in Micro-service Environments,” in International Conference of Service-Oriented Computing, Cham, 2018, vol. 11236, pp. 3–20, doi: 10.1007/978-3-030-03596-9_1. ↩↩↩
-
X. Zhou et al., “Latent error prediction and fault localization for microservice applications by learning from system trace logs,” in Proceedings of the 2019 27th ACM Joint Meeting on European Software Engineering Conference and Symposium on the Foundations of Software Engineering, Tallinn, Estonia, Aug. 2019, pp. 683–694, doi: 10.1145/3338906.3338961. ↩↩
-
M. Ma, J. Xu, Y. Wang, P. Chen, Z. Zhang, and P. Wang, “AutoMAP: Diagnose Your Microservice-based Web Applications Automatically,” in Proceedings of The Web Conference 2020, Taipei, Taiwan, Apr. 2020, pp. 246–258, doi: 10.1145/3366423.3380111. ↩↩↩
-
G. Jeh and J. Widom. Scaling Personalized Web Search. In WWW, 2003. ↩
-
Á. Brandón, M. Solé, A. Huélamo, D. Solans, M. S. Pérez, and V. Muntés-Mulero, “Graph-based root cause analysis for service-oriented and microservice architectures,” Journal of Systems and Software, vol. 159, p. 110432, Jan. 2020, doi: 10.1016/j.jss.2019.110432. ↩↩
-
H. Jayathilaka, C. Krintz, and R. Wolski, “Performance Monitoring and Root Cause Analysis for Cloud-hosted Web Applications,” in Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, Apr. 2017, pp. 469–478, doi: 10.1145/3038912.3052649. ↩↩
-
W. Cheng, K. Zhang, H. Chen, G. Jiang, Z. Chen, and W. Wang, “Ranking Causal Anomalies via Temporal and Dynamical Analysis on Vanishing Correlations,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining - KDD ’16, San Francisco, California, USA, 2016, pp. 805–814, doi: 10.1145/2939672.2939765. ↩↩↩
-
J. Ni et al., “Ranking Causal Anomalies by Modeling Local Propagations on Networked Systems,” in 2017 IEEE International Conference on Data Mining (ICDM), Nov. 2017, pp. 1003–1008, doi: 10.1109/ICDM.2017.129. ↩↩
Created : Jul 15, 2021